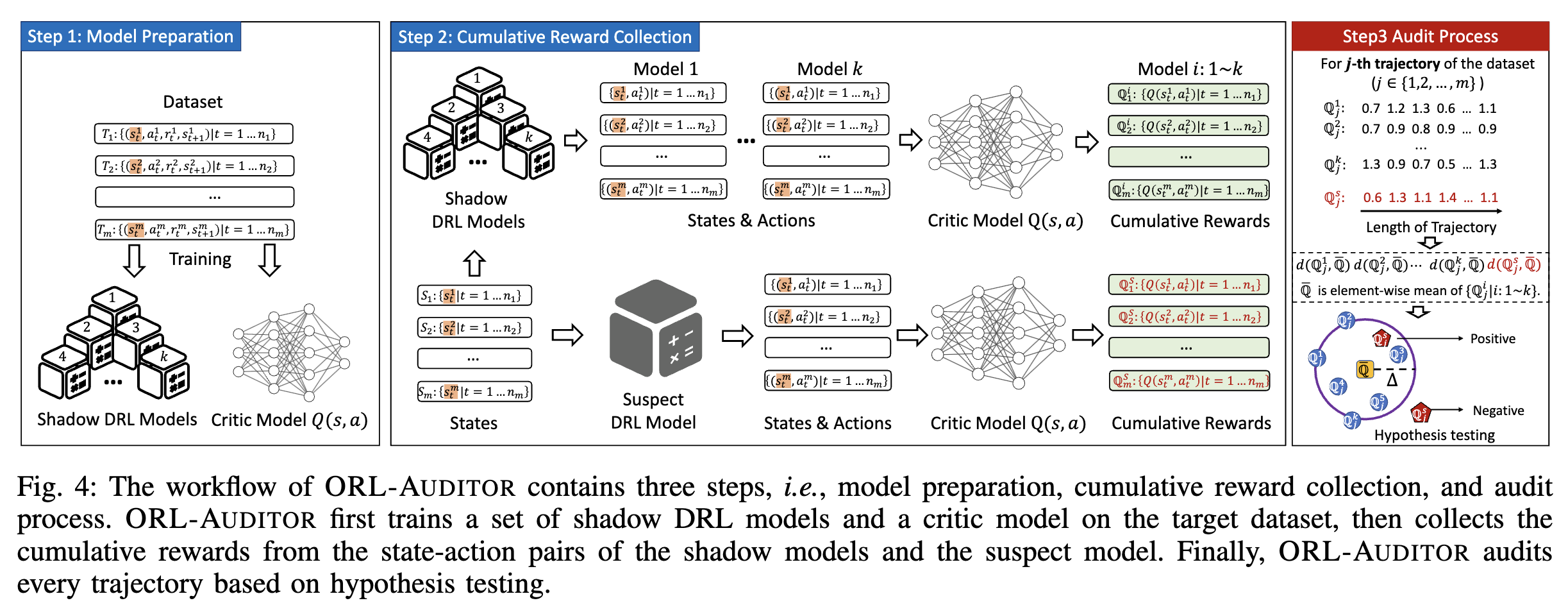
Abstract
Data is a critical asset in AI, as high-quality datasets can significantly improve the performance of machine learning models. In safety-critical domains such as autonomous vehicles, offline deep reinforcement learning (offline DRL) is frequently used to train models on pre-collected datasets, as opposed to training these models by interacting with the real-world environment as the online DRL. To support the development of these models, many institutions make datasets publicly available with opensource licenses, but these datasets are at risk of potential misuse or infringement. Injecting watermarks to the dataset may protect the intellectual property of the data, but it cannot handle datasets that have already been published and is infeasible to be altered afterward. Other existing solutions, such as dataset inference and membership inference, do not work well in the offline DRL scenario due to the diverse model behavior characteristics and offline setting constraints. In this paper, we advocate a new paradigm by leveraging the fact that cumulative rewards can act as a unique identifier that distinguishes DRL models trained on a specific dataset. To this end, we propose ORL-AUDITOR, which is the first trajectorylevel dataset auditing mechanism for offline RL scenarios. Our experiments on multiple offline DRL models and tasks reveal the efficacy of ORL-AUDITOR, with auditing accuracy over 95% and false positive rates less than 2.88%. We also provide valuable insights into the practical implementation of ORL-AUDITOR by studying various parameter settings. Furthermore, we demonstrate the auditing capability of ORL-AUDITOR on open-source datasets from Google and DeepMind, highlighting its effectiveness in auditing published datasets. ORL-AUDITOR is open-sourced at https://github.com/link-zju/ORL-Auditor.
Resources
Citation
@inproceedings{DCSJCCZ24,
author = {Linkang Du and Min Chen and Mingyang Sun and Shouling Ji and Peng Cheng and Jiming Chen and Zhikun Zhang},
title = {{ORL-Auditor: Dataset Auditing in Offline Deep Reinforcement Learning}},
booktitle = {{NDSS}},
publisher = {Internet Society},
year = {2024},
}