Abstract
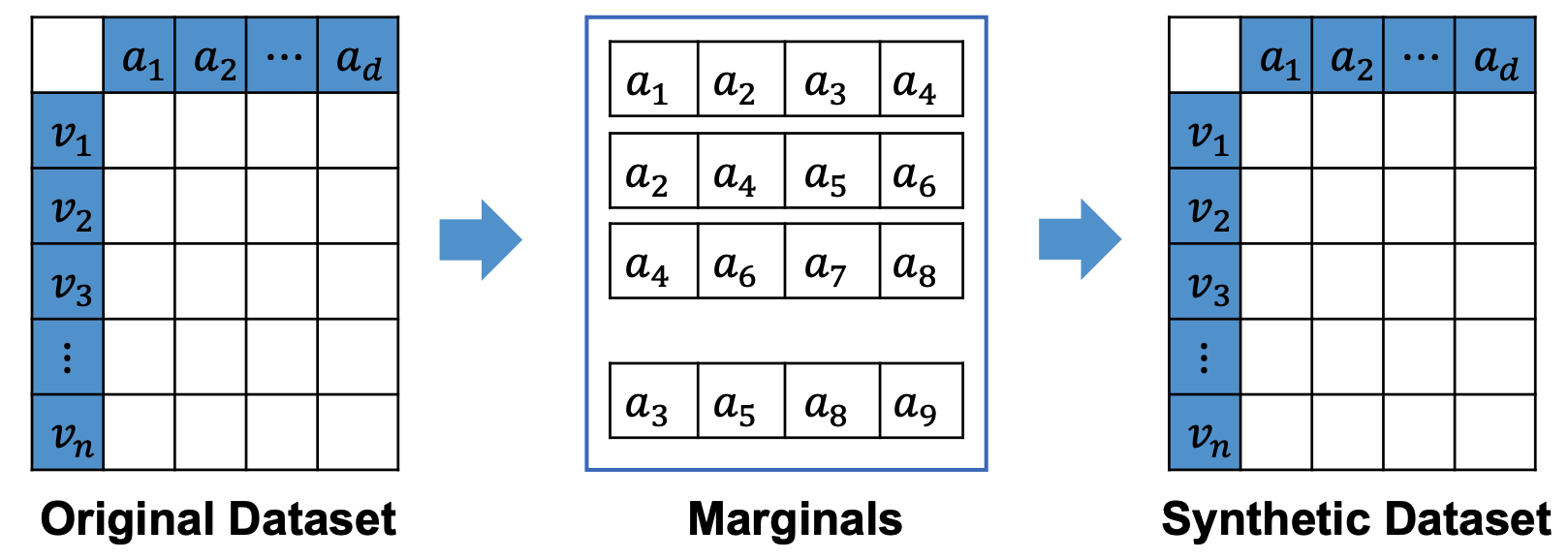
In differential privacy (DP), a challenging problem is to generate synthetic datasets that efficiently capture the useful information in the private data. The synthetic dataset enables any task to be done without privacy concern and modification to existing algorithms. In this paper, we present PrivSyn, the first automatic synthetic data generation method that can handle general tabular datasets (with 100 attributes and domain size >2500). PrivSyn is composed of a new method to automatically and privately identify correlations in the data, and a novel method to generate sample data from a dense graphic model. We extensively evaluate different methods on multiple datasets to demonstrate the performance of our method.
Resources
Citation
@inproceedings{ZWLHBHCZ21,
author = {Zhikun Zhang and Tianhao Wang and Ninghui Li and Jean Honorio and Michael Backes and Shibo He and Jiming Chen and Yang Zhang},
title = {{PrivSyn: Differentially Private Data Synthesis}},
booktitle = {{USENIX Security}},
publisher = {USENIX Association},
year = {2021},
}