Abstract
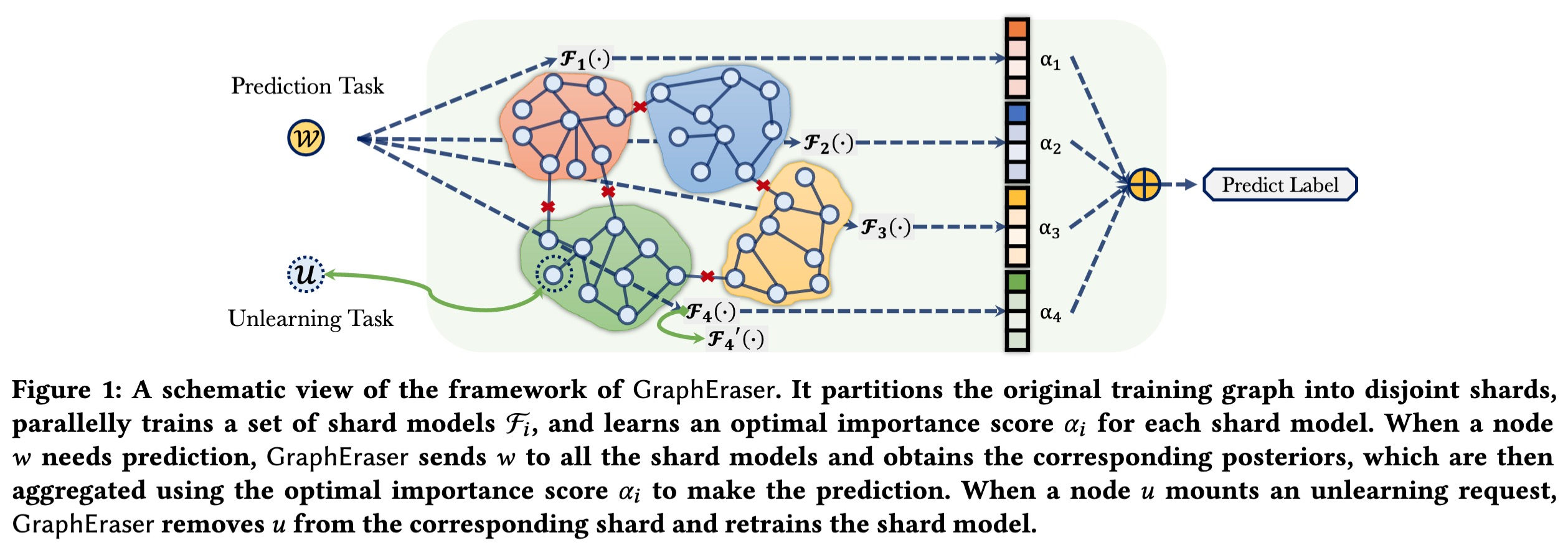
The right to be forgotten states that a data subject has the right to erase their data from an entity storing it. In the context of machine learning (ML), it requires the ML model provider to remove the data subject's data from the training set used to build the ML model, a process known as extit{machine unlearning}. While straightforward and legitimate, retraining the ML model from scratch upon receiving unlearning requests incurs high computational overhead when the training set is large. To affiliation this issue, a number of approximate algorithms have been proposed in the domain of image and text data, among which SISA is the state-of-the-art solution. It randomly partitions the training set into multiple shards and trains a constituent model for each shard. However, directly applying SISA to the graph data can severely damage the graph structural information, and thereby the resulting ML model utility. In this paper, we propose GraphEraser, a novel machine unlearning method tailored to graph data. Its contributions include two novel graph partition algorithms, and a learning-based aggregation method. We conduct extensive experiments on five real-world datasets to illustrate the unlearning efficiency and model utility of GraphEraser. We observe that GraphEraser achieves 2.06× (small dataset) to 35.94× (large dataset) unlearning time improvement compared to retraining from scratch. On the other hand, GraphEraser achieves up to 62.5% higher F1 score than that of random partitioning. In addition, our proposed learning-based aggregation method achieves up to 112% higher F1 score than that of the majority vote aggregation.
Resources
Citation
@inproceedings{CZWBHZ22,
author = {Min Chen and Zhikun Zhang and Tianhao Wang and Michael Backes and Mathias Humbert and Yang Zhang},
title = {{Graph Unlearning}},
booktitle = {{CCS}},
publisher = {ACM},
year = {2022},
}